Key Stages in Biomarker Identification and Validation

Written By: Damon Anderson, PhD
Oct 18, 2017
Whether protein, post-translational modification, or small molecule metabolite in origin, biomarkers hold great promise as diagnostic and prognostic indicators of disease. There have been huge leaps in technology in order to interrogate a larger spectrum of compound sources with greater accuracy and resolution than previously seen. Thus, the potential for biomarker identification is greater than ever before. However, verification of the statistical and biological significance of each candidate, as well as validation of the sensitivity and specificity of these candidates, remain arduous and challenging processes -- with no promises of success.
The old adage, "The best laid plans of mice and men often go astray", may apply to biomarker research as well. However, the more succinct the experimental plan, the less chance that it is experimentation that goes astray rather than the natural course of the science behind it.
In the discovery stage of biomarker research, wide paths are taken for deep interrogation of research samples. Many modern approaches assist this early stage.
Sample complexity - protocols, reagents, and processing steps are designed to reduce sample complexity without losing sensitivity. Examples: Solid phase extraction (SPE) for removal of high abundance matrix background proteins using a chromatographic support, Liquid-liquid extraction for selective removal of matrix compounds using phase change precipitation, and simple chemical precipitation.
Analyte enrichment - materials are used to pull compound fractions out of complex backgrounds in order to assist the identification of candidates. Examples include: beads or pipet tips coated with lectins or phosphopeptide binding compounds, extensive prefractionation to reduce the abundance and potential negative affects of background material. Preventing activities such as inhibitory binding, co-precipitation, or others, these latter methods assist in elevating the presence of candidates which are no longer masked or are now better reported by the instrument.
The abundance of advanced processing techniques described above expands the search space for biologically relevant compounds, thereby boosting the chances of biomarker identification. Examples of this expanded space include: a wider range of cell types and cellular fractions, a broader depth of tissue distribution; a more diverse level of analysis in proximal solutions, such as urine or cerebral spinal fluid, across human and model systems; and critical analysis in blood plasma, the 'gold standard' for biomarker relevance.
Biomarker discovery can include screening of thousands of analytes across tens to hundreds of samples, so well designed and robust protocols are mandatory for success at this stage
The next stage can be divided into qualification and verification.
Qualification is meant to confirm the differential abundance of candidates in human plasma. Whereas, verification begins to assess the specificity of candidates as biomarkers of disease by the use of population-derived sample cohorts.
This stage makes use of refined sample pretreatment or prefractionation and includes modifications for compatibility with a more quantitative workflow -- and the reagents, methods, and analytical tool that go along with this. Examples include: immunoaffinity enrichment of specific candidate peptides and labelled or label-free quantitation of these peptides by multiple reaction monitoring (MRM) LC-MS/MS.
Based on the statistical significance of the presence or absence of candidate markers compared to control samples, the biological relevance of potential biomarkers come into better focus. These measures of quantitative specificity bring the number of analytes down 1 to 2 orders of magnitude arriving at 10s to 100s of compounds. At the same time the size of the sample cohorts climb to the 100s.
The final stage of biomarker validation and clinical assay development involves refined investigations into specificity and sensitivity as well as assay process and logistics optimization.
This stage requires population-derived human plasma from large well-defined patient cohorts. These 1000+ sample cohorts will include clinical data such as base level metabolic factors, general pathological indicators, and perhaps data for the existing 'gold standard' -- the previous biomarker. With methods now extremely well-defined, the new objective involves statistical analysis of the specificity and sensitivity of a candidate biomarker compared to existing tests for indication of disease. This may include comparison of receiver operating characteristic (ROC) analysis of each marker in order to determine which generates a better true positive rate (sensitivity) versus false positive rate (1-specificity). The ROC plot closest to unity has the highest level predictive value over the others.
Traditionally the domain of immunoassays, validated and optimized MS-based laboratory developed tests have now become abundant in the clinical and R&D spaces. The continued development of sample treatment techniques and products, analytical instrument technologies, and data interpretation software and database resources will bring biomarker assays closer to FDA approved clinical diagnostic use. As well, these developments will assist the therapeutic development processes by providing better indicators of therapeutic efficacy and off target effects, in turn producing safer and more effective medicines.
The road to biomarker validation is long and arduous, however modern solutions are paving the way for an ever greater range of entities with untold potential.

Apr 01, 2025
Product News
Helium 1 µL Spectrophotometer from DeNovix
Affordable and accurate, the Helium 1 µL Spectrophotometer by DeNovix offers fast, nanovolume quantification for DNA, RNA, and protein analysis.

Mar 27, 2025
Product News
Next-Gen PHCbi CO₂ Incubator Elevates Contamination Control and Sustainability
Discover the PHCbi MCO-171AICUVD-PA CO₂ incubator with copper alloy chambers, UV-LED disinfection, and 180°C sterilization—engineered for lab sustainability and precision.

Mar 26, 2025
Product News
Revolutionize Cell Analysis with the CytoFLEX Mosaic Spectral Detection Module
Upgrade your flow cytometry with the modular CytoFLEX Mosaic Spectral Detection Module—offering up to 88 detection channels and superior nanoparticle sensitivity.

Mar 25, 2025
Product News
Hamilton Introduces PSD SmartSense Pump
Discover Hamilton’s PSD SmartSense Pump, combining compact design, smart sensors, and precision syringe-drive technology for advanced OEM liquid handling.

Mar 24, 2025
Product News
Reliable Cold Storage for Labs: Thermo Scientific™ TSG Series Freezers and Sample Prep Refrigerators
Discover the Thermo Scientific™ TSG Series—eco-friendly, quiet refrigerators and freezers engineered for consistent, secure lab sample storage.
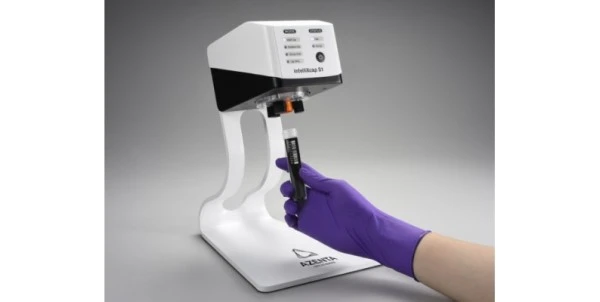
Mar 21, 2025
Product News
Automated Tube Capping for Large-Format Tubes: IntelliXcap S1
Automate large-format tube capping with IntelliXcap S1—ergonomic, consistent, and compact for lab workflows from low to high throughput.

Mar 20, 2025
Product News
Porvair Sciences Introduces Clara™ 6 Well Cell Culture Plates for Enhanced Cell Growth
Discover Porvair Sciences’ Clara™ 6 Well Cell Culture Plate, designed for high-yield cell growth, gentle media swirling, and full automation compatibility.

Mar 19, 2025
Product News
New Intelligent Precision Balance Scale from Paul N. Gardner Company
Discover the Intelligent Precision Balance Scale from Paul N. Gardner Company. High capacity (3,200g), precision (0.01g), and advanced features for lab & industrial use.

Mar 18, 2025
Product News
Malvern Panalytical Hosts Future Days: Focus on Battery
A Virtual Event Exploring Innovations in Battery Technology

Mar 13, 2025
Product News
Thermo Scientific Transcend VTLX-1 UHPLC System
Boost LC-MS efficiency with the Thermo Scientific Transcend VTLX-1 UHPLC system, featuring automated sample cleanup and high-throughput processing for complex matrices.