2018 Mass Spectrometry Emerging Technology Outlook

Written By: Damon Anderson, PhD
Jan 24, 2018
With the new year comes the promise of greater mass spectrometry performance, more powerful analysis solutions, and a broader scope and depth of interrogation than previously seen. Many areas of research stand to gain from developments in the field.
In this article we focus on three domains likely to get significant boosts in the new year and beyond – Proteomics, Metabolomics, and Biotherapeutics. As well, we explore additional areas slated for new developments in subsequent articles – specifically Clinical Applications, Imaging Technologies, and Compact Mass Spectrometry. This year will see advances in enabling technologies and innovative answers to challenges, both existing and new. As such, 2018 will be yet another important mark on the interesting evolutionary journey of biological mass spectrometry.
Mass spectrometry applications in proteomics
The field of proteomics has evolved significantly in recent years due to advances in mass spectrometry on multiple fronts. On the front end, sample extraction, LC and separations efficiency, and high-resolution mass accuracy of MS instrumentation have all played a role. On the backend, novel computational solutions and increasingly curated and validated databases have helped the process as well. The advent of innovative labeling and label-free techniques has brought quantitative analysis to the forefront. These developments have enabled, not only a deeper identification of protein targets, but the realization of biomarkers with potential therapeutic value. This has led in certain cases to the validation of mass spectrometry assays for clinical use.
Beyond the technical and clinical innovation lies the potential for precision medicine. Advancements along this front have been and continue to be met with confounding factors – issues that will require solutions if this new age of medicine is to be fully realized.
Data robustness and reliablity
An important issue that has plagued proteomics biomarker research involves the robustness and reliability of the data. Searches for biologically relevant biomarkers of disease are confounded by both physiological and technical details. Disease patients often express factors and proteins which are the result of immune reaction or comorbidities related to a given disease indication. These factors not only convolute the detection of disease proteins, which may be present in much lower abundance, but they can stand out as false positives upon comparison with healthy patients.
As more complete annotation of immune and other housekeeping proteins and protein databases are refined, it is hoped that more robust changes can be resolved. Novel extraction techniques to more efficiently remove high abundance immune and metabolic proteins in blood and other sample types will also advance this goal. In concert to these improvements, increased scale and cohort sizes will add statistical power to biomarker discovery efforts.
Practical considerations of big data
Another issue that has grown in relevance more recently involves the practical implications of “big data”. More powerful technologies and larger sample cohorts equate to dramatically larger and more complex experimental data sets. This presents problems not only for data analysis, but for data storage logistics as well. This conundrum is not exclusive to proteomics, as other fields such as imaging microscopy, and DNA and RNA deep sequencing have witnessed similar issues with mounting stacks of instrument-derived data. Computational approaches in these fields are being pursued in order to parse the informative data while diverting uninformative details, in attempts to more easily manage the workload. Lessons learned elsewhere may prove fruitful in addressing the big data issues in proteomics.
Data annotation and integration
Other issues implicit to modern proteomics include data annotation and integration limitations. Proteomics data is often submitted to databases in order to assign identity and define interconnectivity and systems level pathway analysis. The result of such analysis is often a function of the database tool(s) used for the work.
Future analysis will be enhanced by higher quality mathematical modeling and algorithms designed to allow better, more complete integration of robust proteomics data. This sizable effort will be supported by more complete repositories to access and qualify proteomics data.
Mass spectrometry applications in metabolomics
Metabolomics defined is essentially the analysis of the small molecules present in the body due to metabolism and those ingested from the surrounding environment, such as chemicals, drugs, and pesticides. The analysis of these metabolites has recently been utilized to discover new markers of disease and perturbed metabolic pathways. Metabolomic analyses can be performed with either targeted or untargeted measurements.
Targeted and untargeted metabolomics
In targeted studies, only a small subset of metabolites is analyzed. Untargeted measurements, on the other hand, study all possible small molecules in an experiment, relying on high resolution mass spectrometry to precisely measure the m/z values across many samples. Untargeted measurements are typically coupled to either gas or liquid chromatography or ion mobility as the retention time or the mobility provides an important secondary distinguishing characteristic of each specific metabolite. It is expected that both targeted and untargeted metabolomic measurements will have increasing importance in future research and clinical studies.
Given the growth of metabolomics over the past several years, the use of high resolution mass spectrometry has rapidly progressed in step. High resolution approaches to measure small molecules offer several advantages for clinical analyses such as confirmation via accurate mass of the precursor and product ions and an evaluation of the isotopic abundance. Emerging high resolution mass spectrometry approaches will continue to advance both quantitative and semi-quantitative analyses in metabolomics.
Mass spectrometry applications in biotherapeutics
Increased demand for new drugs and novel therapeutic targets has meant a greater interest in exploring the therapeutic potential of less abundant cellular proteins and biomarkers.
Instrument sensitivity and efficiency
In addition to advancements in method efficiency and instrument sensitivity, the field will require improved quantitation techniques for biologics such as: antibodies, protein complexes, RNA, and protein conjugates. This is especially relevant in high molecular weight species which require both bottom up and top down methods.
Sample extraction techniques
Sample extraction techniques continue to evolve to address the inherent challenges of pulling biological molecules from their sources and making them amenable to ionization, while at the same time preserving native composition. Extraction techniques such as immune-affinity enrichment will continue to be refined to increase specificity, yield, and robustness, for both on-line and off-line approaches.
Multi-dimensional seperations
Separations technologies also continue to expand. With the implementation of a broader array of columns and techniques to increase orthogonal separation, high resolution MS instruments will see increasingly complex and informative sample sets. High-throughput applications will reap the benefits of more efficient and automatable extraction methods, as well as robust and powerful separations techniques.
With the increase in sample complexity and high-throughput data generation comes the necessity for big data solutions. High-resolution mass approaches couple both high-performance instrumentation with powerful data analysis platforms in order to perform accurate identification. Multiplex label-free quantitation combined with advanced statistical analysis means samples can be measured and biological processes interrogated with greater depth than before.
Mass spectrometry and new technologies
Listed below are areas ripe for further development in 2018 and beyond.
Sample preparation:
- New types of extraction methods: affinity techniques, molecularly imprinted polymers (MIPs), aptamers, functionalized pipette tips (MSIA), electroextraction, QuEChERS, SISCAPA, microextraction.
- New sources for sample analysis: dried blood spots (DBS) and dried plasma spots (DPS).
Sample ionization techniques:
- Enhancements in automatable on-line separation technologies.
- The evolution and implementation of novel ambient ionization techniques.
- The continued refinement of techniques including: electrospray ionization (ESI), nano ESI, micro ESI, atmospheric pressure chemical ionization (APCI), atmospheric pressure photoionization (APPI), matrix assisted laser desorption ionization (MALDI), DESI, and others.
Mass analyzers:
- Developments and improvements in mass analyzers including: linear ion traps, FTMS, time-of-flight (TOF), orbitraps, and accelerator mass spectrometry (AMS), the latter currently being applied to micro-dosing experiments by the pharmaceutical industry.
- Solutions for issues involving full-scan acquisition rates, high-resolution mass spectrometry (HRMS), and exact mass measurements for qualitative and quantitative analysis.
- A focus on improvements in analytical merits of high-resolution MRM methods compared with modern SRM LC/MS approaches – particularly for clinical applications.
General considerations:
Instrument Robustness – Efficiency – Standardization - Data Analysis and Annotation - Information Integration – Data Storage.

Apr 01, 2025
Product News
Helium 1 µL Spectrophotometer from DeNovix
Affordable and accurate, the Helium 1 µL Spectrophotometer by DeNovix offers fast, nanovolume quantification for DNA, RNA, and protein analysis.

Mar 27, 2025
Product News
Next-Gen PHCbi CO₂ Incubator Elevates Contamination Control and Sustainability
Discover the PHCbi MCO-171AICUVD-PA CO₂ incubator with copper alloy chambers, UV-LED disinfection, and 180°C sterilization—engineered for lab sustainability and precision.

Mar 26, 2025
Product News
Revolutionize Cell Analysis with the CytoFLEX Mosaic Spectral Detection Module
Upgrade your flow cytometry with the modular CytoFLEX Mosaic Spectral Detection Module—offering up to 88 detection channels and superior nanoparticle sensitivity.

Mar 25, 2025
Product News
Hamilton Introduces PSD SmartSense Pump
Discover Hamilton’s PSD SmartSense Pump, combining compact design, smart sensors, and precision syringe-drive technology for advanced OEM liquid handling.

Mar 24, 2025
Product News
Reliable Cold Storage for Labs: Thermo Scientific™ TSG Series Freezers and Sample Prep Refrigerators
Discover the Thermo Scientific™ TSG Series—eco-friendly, quiet refrigerators and freezers engineered for consistent, secure lab sample storage.
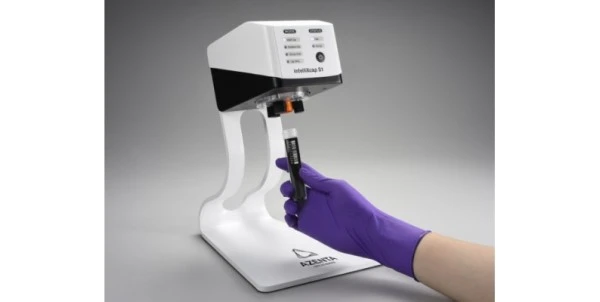
Mar 21, 2025
Product News
Automated Tube Capping for Large-Format Tubes: IntelliXcap S1
Automate large-format tube capping with IntelliXcap S1—ergonomic, consistent, and compact for lab workflows from low to high throughput.

Mar 20, 2025
Product News
Porvair Sciences Introduces Clara™ 6 Well Cell Culture Plates for Enhanced Cell Growth
Discover Porvair Sciences’ Clara™ 6 Well Cell Culture Plate, designed for high-yield cell growth, gentle media swirling, and full automation compatibility.

Mar 19, 2025
Product News
New Intelligent Precision Balance Scale from Paul N. Gardner Company
Discover the Intelligent Precision Balance Scale from Paul N. Gardner Company. High capacity (3,200g), precision (0.01g), and advanced features for lab & industrial use.

Mar 18, 2025
Product News
Malvern Panalytical Hosts Future Days: Focus on Battery
A Virtual Event Exploring Innovations in Battery Technology

Mar 13, 2025
Product News
Thermo Scientific Transcend VTLX-1 UHPLC System
Boost LC-MS efficiency with the Thermo Scientific Transcend VTLX-1 UHPLC system, featuring automated sample cleanup and high-throughput processing for complex matrices.